How does a scheduler work?
When you submit a job, it enters a job queue. A scheduler reads the job requirements from all submitted job scripts and determines when, and on which nodes these jobs should run.
The scheduler tries to fulfill three conditions:
- Use the HPC system as efficiently as possible, i.e. leave as few nodes idle as possible.
- Give higher priority to jobs that have been in the queue for a long time.
- Give higher priority to institutes/users that have not used much budget yet (known as a 'fair share' system).
How long a job remains in the queue depends on these factors, as well as on how busy the system is overall. In general, smaller jobs (jobs requiring only a few processors and/or little time) are somewhat more easy to fit in than large jobs.
It is possible to get an estimate of when a job will start according to the current queue with the squeue command (e.g. squeue -j <jobid> -o "%.18i %.9P %.8j %.8u %.2t %.10M %.6D %R %S"). This estimate is notoriously unreliable, as every time a job is submitted, deleted or completed, the queue will change - and with it your expected start time. It may however give you some indication of whether your job will starts in a couple of minutes, hours or days.
Below is an example showing how a set of jobs entering the queue is handled by the scheduler.
Wait time in the queue
We receive many questions from users regarding wait times in the queue, mostly because the behaviour of the scheduler is not always easy to understand and predict. Here are some scenarios that may surprise you, but are in fact perfectly normal:
| Situation | Explanation |
|---|---|
| A job that was submitted after yours, starts earlier. | The new job has a higher priority because it comes from an institute/user that has not spent much budget yet, or the new job fills a gap in the schedule that your job is too big for. |
| Sufficient processors are available, but your job does not start. | Another job that has higher priority than yours (e.g. because it was submitted earlier) is waiting for even more processors to become available before it can start. |
| Last month, your job started immediately, but a similar job has now been in the queue for several days. | The system load varies a lot from time to time. Additionally, the priority of your job compared to other jobs may differ, also affecting your wait time. |
| Your job has been in the queue for several days, and has not started yet. | A wait time of several days is not uncommon for cluster computers. As cluster computers aim to perform calculations that would take months or even years on a regular PC, a couple of days waiting is generally considered acceptable. |
Fair share
As mentioned above, a fair share algorithm is used: when a user, or group of users are using more of the system than their pre-determined share, the priority of their corresponding jobs are lowered. This ensures that over time the share of the system used approaches the pre-determined value.
Back-filling
The scheduler will take advantage of nodes that are allocated to a (usually large job) which hasn't started yet, by running smaller and shorter jobs on those nodes, even if those jobs where placed in the queue later. See the example below, specifically what happens to jobs D and E.
Because of the back-filling behaviour it is important to realize that the more accurate the estimation of the running time of a job is, the more chances there are that the job can get scheduled on a set of waiting nodes (in the example below job G could have been scheduled after job B, if the estimated running time was shorter). Of course, your job might need a long running-time in order to finish what you intend it to do, but if you can shorten the wall-time you request for the job this might have a favorable effect on when it gets scheduled.
A scheduling example
The scheduler is particularly apt for parallel computing systems, where jobs get exclusive access to nodes (or a subset of a node's cores) they get from the batch system. Here we try to explain how it works, as some behaviour of the scheduler might be surprising.

In the above picture, the horizontal axis represents the available nodes in the HPC system. The vertical axis represents time, with the current time at the bottom, moving into the future as we go up. At this moment, the HPC system is empty, none of the nodes are being used.
In the steps below a job is represented as a rectangle: the horizontal size representing the number of nodes the job needs, the vertical size representing the time left for executing the job. Initially, the vertical size of a job is the wall-clock time requested by the user when entering the job in the scheduler queue.
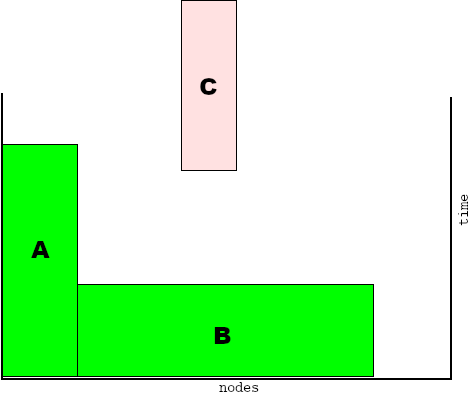
Here we see that now two jobs are running (job A and job B) and that job C, that is at the front of the queue, needs to be scheduled before it can start to run. "Scheduling" here means finding the right set of free nodes to run on. It is obvious that there is place enough to accommodate job C, so it will run immediately on unused nodes.

Next, with the appearance of job D, there is a problem: there are not enough free nodes to accommodate that job immediately. So, the scheduler places job D on top of job B and C, meaning that when both B and C have finished and the nodes they used become available job D can run on those nodes.
Note that by now the time remaining on the running jobs A, B and C has decreased.
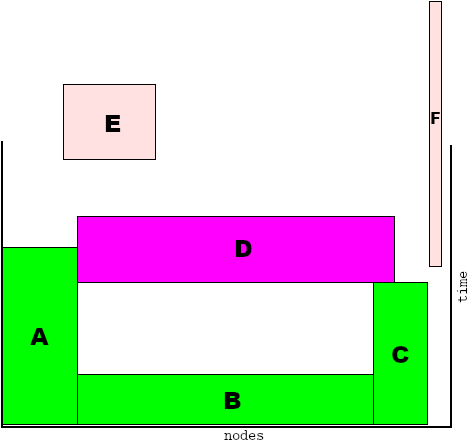
Jobs E and F have arrived. We see, that job E can be scheduled before job D, because job D can only run after job C finishes and the empty "space" below D and above B will fit E. So even though job E was placed in the queue after job D, it will run before it. So now job D depends on jobs B, C and E to finish before it can run itself.
Job F can be scheduled alongside job C using some of the last remaining free nodes, without hindering any other job, so it starts immediately. Again, job F was queued after job D, but starts before it.

Now, job G, a rather large job, arrives. There is no space for it below job D or anywhere else, so it will be put on top of job D.
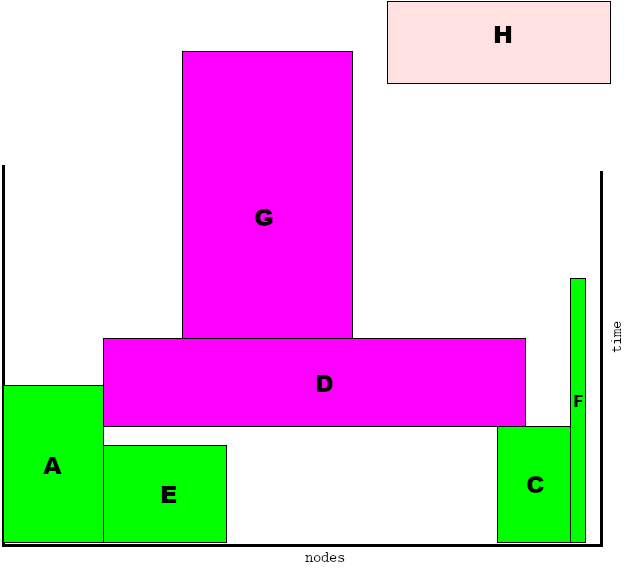
At this point job B has ended. Job G could start now (instead of job D), and indeed could be a valid scheduler choice. In this case, however, job G has to wait because other jobs were submitted earlier. But the owner of job G might be surprised: there are enough nodes free for his/her job, but his job is not started! Job H, however will be started immediately, as it fits nicely in the hole under job D. Note that job D can still only start after C (and E) are done. Also note that starting job H does not delay the expected start times of other jobs.
Remarks
Of course, some simplifications in the explanation above were made: the pictures suggest that a job always gets a contiguous row of nodes, which in general is not the case. Also jobs tend to run in shorter time than the submitter asked for. But these things do not matter too much, the scheduler determines what has to be done after each event (the appearance of a job, the termination of a job and so on).
Jobs that have started running are fixed, meaning they keep running and on the set of nodes that was assigned to them. But the scheduler takes the incoming jobs in order of appearance and plays a kind of 'tetris' with them as we showed in the example. It is obvious that a submitted job is guaranteed to run at some point in the future. The only change can be that other jobs end earlier than predicted, so any job waiting on those can start earlier than initially planned. This mechanism is very flexible. It is possible to give a job a higher priority by simply assuming that it was submitted earlier, or vice versa, that it was submitted later. When one uses this to alter priorities, especially with multiple jobs in the queue, the effect is that the starting time of jobs becomes less predictable. But still, there is a guarantee that eventually a job will run. In practice some extra measures are taken to prevent that one user fills athewhole HPC system with his/her jobs for a week or more. The priority mechanism is used for that purpose.
As you can see the scheduler has to juggle a lot of things all at once, as in practice there are many more factors it considers than shown here. For example, the different queues (partitions) each have their own settings, there are usually different types of nodes in the system (thin vs fat, CPU types, etc) which jobs can request in varying combinations, and future reservations of (part of) the system due to planned maintenance, hardware errors and other factors will make the scheduler's job more difficult. All in all, scheduling is a hard optimization problem and the behaviour of the scheduler might be non-intuitive because of this. Perhaps the worst restriction is that the scheduler needs to act in real-time to all the things happening in the system, and can't spend (say) minutes on deciding where to schedule a job that just was placed in the queue. Especially when there are a few hundred users on the system that each want to have their jobs run as quickly as possible.